https://core.ewha.ac.kr/publicview/C0101020140502151452123728?vmode=f
반효경 [운영체제] 20. Memory Management 3
설명이 없습니다.
core.ewha.ac.kr

전수업에서는 2단계의 페이지 테이블이 돌아가는것을 봤는데 페이지 테이블이 2단계 만이 아니라 다단계로 사용할수도 있다.
이러면 테이블을 위한 공간을 줄일수 있는데 그만큼 주소변환 한번 할때마다 페이지 테이블을 여러번 거쳐야하고
페이지테이블이 메모리에 있기때문에 4단계 페이지 테이블이라면 5번 메모리에 접근해야하는 문제가 있다.
TLB를 이용해서 줄일수있지만 미스가 나면 오버헤드가 크긴하다.
하지만 대부분 TLB내에서 해결되는 편이라서 이런 멀티레벨 페이지 테이블도 가능하다.

자료를 보자면 첫번째 있는것이 프로그램마다 주어지는 로지컬 메모리이고
세번째 것이 물리적 메모리이다.
그리고 중간의 페이지 테이블을 통해서 주소 변환을 하는것이다
여태까지는 그냥 프로그램의 로지컬 메모리의 페이지 수만큼 엔트리가 있고
그에 대응하는 프레임 넘버만 존재한다고 배웠는데
사실 valid invalid bit라는 것이 존재한다.
메모리에 의미있는 것을 넣지 않더라고 엔트리의 갯수는 조절할수가 없다(배열로 되어있으니까 index로 접근해야해서)
그래서 자료에서 보면 페이지가 5까지 있는데 테이블은 엔트리가 6,7도 있다.
그래서 6,7은 사용이 되지 않으니까 invalid비트로 안쓰는 부분을 표시한다
valid 라는 상태는 실제로 물리적 메모리에 그 페이지가 올라가있다는것이고
invalid는 이 페이지가 이 프로그램에의해서 사용되지않거나 현재 메모리가 올라가있지 않은 상태이다(하드디스크에 단순히 있는 상태 아직안올라감)

그리고 사실 protection bit 라는 비트가 또 하나 더있다.
이 비트는 어떤 연산에 대한 접근권한을 표시한다. 그 페이지들에 code,data,stack 들이 각각 page에 나눠서 담겨있을것인다 근데 code 같은경우에는 내용이 안바뀌어야하니까 read-only로 세팅해놓고 data,stack 같은경우 read,write 권한을 줘야한다
그것을 표시하기위한 bit 이다.

여태까지 페이지 테이블이 문제가 되는것은 많은 용량을 차지하고있다는것이다
->페이지 테이블 자체가 메모리 공간을 많이 차지한다.(공간 오버헤드가 크다)
이런 문제점을 해결해보고자 나온 페이지 테이블이다
이것도 TLB 처럼 순차탐색의 오버헤드를 병렬적인 탐색을 할수있는 associative register 을 통해 줄인다.

원래의 페이지테이블을 통한 주소변환을 역으로 바꿔놓은것이다.
원래는 페이지테이블이 프로세스 마다 있었다.
근데 인버티드 페이지테이블은 시스템안에 페이지테이블이 딱하나 존재한다.-> 프로세스 별로 만들어지는게아님
페이지 테이블의 엔트리가 프로세스의 페이지 갯수만큼 존재하는것이 아닌
피지컬메모리의 프레임 갯수만큼 존재한다(물리적 메모리가 기준)
설명이 좀 못알아듣게 하시는데
페이지 물리적 메모리에서 f번째에 pid가 들어있다는걸 표시하는것같아 즉 완전 찾는방법도 역이다.
주소 변환은 논리주소로 물리주소를 얻어내는 것인데 이것은 취지에 맞지 않다 그래서 어떻게 변환하는지 보면
페이지 테이블 엔트리를 다뒤져서 p를 찾아내면 그게 f번째 프레임에 있다는것을 알수있다
테이블은 index로 빠른접근이 가능한데 이건 시간복잡도를 포기해야한다.
그리고 어떤 프로그램의 페이지인지 알아야하므로 여기서는 pid 값도 가지고있어야한다
굉장히 쓸데없고 영양가 없다.

프로그램을 구성하는 페이지들 중에는 다른 프로세스들과 공유할수 있는 페이지들이있다.
쉐어드 코드 이름이 다양하다 리 엔터 코드, 퓨어 코드 등등

예를 들어 지금 이 자료와 같은 상황이 프로세스 세개가 다 워드이다 워드 3개 돌리는것인데 이 3개의 코드 부분의 페이지는 동일한것을 써도 될것이다. 같은 프로그램이니까
이렇게 공유할수있는 코드를 shared code 라고 부르는데 이런것들을 각각 코드를 올리는것이 아니라 1copy만 물리적 메모리에 올리는 방법을 사용한다.
예시를 보면 물리적메모리에 코드부분은 하나만있고 페이지 테이블이 같은곳을 가리키는것으로 되어있다.
이러한 쉐어드 코드는 두가지를 만족해야한다
1.공유할수 있는 코드를 read only 로 해서 하나만 메모리에 올리게 된다
2.쉐어드 코드는 동일한 logical address 에 위치해야한다. -> 쉐어드 코드에 해당하는 페이지가 동일한 로지컬 어드레스에 위치해야한다.
같은 코드더라도 위치가 다르면 안된다. 코드는 같은데 순서가 다를수 있으니까
이거 쉐어드 메모리와 IPC 와는 다르다 이것들은 프로세스 간의 통신을 목적으로 메모리를 공유하는것이고(read,write 다됨)
이것은 같은내용이 겹치게 올라가는것을 효율성을 위해서 사용하는것이다(only-read)
페이징은 여기서 마무리한다.

세그멘테이션 기법
프로세스를 구성하는 주소공간을 의미단위로 쪼갠것이다 ex) code,data,stack
좀더 잘게 쪼개면 함수 하나하나가 세그먼트로 쪼갤수있다.

세그멘테이션에서 주소변환은 페이징 기법이랑 어느정도 비슷하다.
세그먼트 번호와 세그먼트 안에서 얼마나 떨어져있는지 offset으로 구성되어있다.
각 세그먼트 별로 다른 메모리 주소에 올라가기 때문에
세그먼트 테이블이 존재한다.
각엔트리들이 base와 limit 를 가지고
주소 변환을 위해서 base 레지스터,리미트 레지스터가 있는데 -> base는 세그먼트의 시작위시,limit는 세그먼트의 길이를 나타낸다.
STBR은 세그먼트 테이블의 위치
STRL은 세그먼트의 수를 나타낸다.
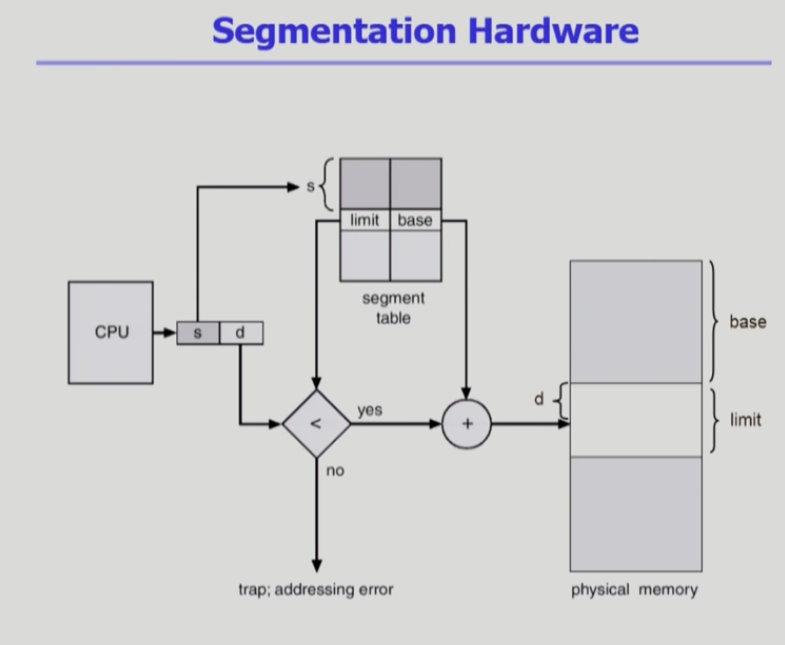
세그먼트의 주소 변환을 나타내는 도식이다
우선 cpu에서 논리주소를 주는데 세그먼트의 번호와 offset을 준다.
그럼 세그먼트 테이블에 있는 정보다 paging 과 조금 다른데 base(메모리 어디에있는지) 와 함께 limit라고 세그먼트의 크기를 나타내는 값이있다 세그먼트가 모두 같은 크기를 갖지않기 때문이다.
주소 변환을 할때 크게 두가지를 체크하는데
1. 논리주소의 세그먼트 번호가 STLR값보다 작은지 체크한다 세그먼트 수보다 더큰 세그먼트를 요청하는것 아닌지 체크
2.세그먼트의 길이 보다 더 떨어진 offset인지 체크
이것들을 통과하면 주소를 변환한다.
주소변환방법은 base에 offset더하는거로 똑같다.
페이징 기법과 다른 부분은
시작주소가 페이징에서는 페이지 번호로 주어졌는데
세그멘테이션에서는 세그먼트가 어디서 시작됐는지 정확한 바이트단위 주소로 매겨줘야한다.
이제 앞쪽에서 HOLE 생긴것처럼 세그먼트도 크기가 균일하지 않기 때문에 같은 현상이일어난다

외부조각이 발생하기에 first fit/best fit 이런것들을 써줘야한다.
장점은 의미단위로 일하기 때문에 protection 같은 경우에 훨씬 효율적이다.
쉐어링도 의미단위라서 훨씬 효율적이다
이유는 당연히 생각해보면 이해가될것이다.
page 하나에 code,data 이런게 겹쳐있을수있고 이상황에서 참 애매해진다.
'cs > 운영체제' 카테고리의 다른 글
| 19 강 Memory Management 2 (1) | 2023.02.01 |
|---|---|
| 18강 Memory Management 1 (1) | 2023.01.30 |
| 17강 Deadlocks 2 (0) | 2023.01.24 |
| 16강 Deadlocks 1 (0) | 2023.01.24 |
| 15강 Process Synchronization 4(Concurrency Control) (0) | 2023.01.24 |



